Neural Trojans and how you can help
Attackers can inject “Trojans” into neural networks that cause them to fail, potentially catastrophically, in unknowable situations. Machine learning models are becoming increasingly accessible and training and deployment pipelines are becoming increasingly opaque, exacerbating this security concern. You can contribute by proposing your own defenses: a number of researchers and I are running a $50K NeurIPS 2022 competition called the Trojan Detection Challenge, and we’d love to see you participate.
Introduction
You’ve probably heard of Trojan horse malware. As in the Trojan Horse that enabled the Greeks to enter Troy in disguise, Trojans appear to be safe programs but hide malicious payloads.
Machine learning has its own Trojan analogue. In a neural Trojan attack, malicious functionality is embedded into the weights of a neural network. The neural network will behave normally on most inputs, but behave dangerously in select circumstances.
From a security perspective, neural Trojans are especially tricky because neural networks are black boxes. Trojan horse malware is usually spread via some form of social engineering - for instance, in an email asking you to download some program - so we can to some extent learn to avoid suspicious solicitations. Antivirus software detects known Trojan signatures and scans your computer for abnormal behavior, such as high pop-up frequency. But we don’t have these sorts of leads when we want to avoid neural Trojans. The average consumer has no idea how machine learning models they interact with are trained (sometimes, neither does the publisher). It’s also impossible to curate a database of known neural Trojans because every neural network and Trojan looks different, and it’s hard to develop robust heuristic-based or behavioral methods that can detect whether model weights are hiding something because we barely understand how model weights store information as it stands.
The first neural Trojan attack was proposed in 2017. Since then, many Trojan attacks and defenses have been authored, but there’s still plenty of work to be done. I’m personally quite excited about this research direction: the problem of neural Trojans has obvious immediate security implications, and it also resembles a number of other AI safety domains, the progress of which plausibly correlates with progress on Trojans. I’m writing this post with the goal of field orientation and motivation: if you read the whole thing, you’ll ideally have the information you need to start imagining your own attacks and defenses with sufficient understanding of how your strategy relates to existing ones. You’ll also ideally be able to picture why this might be a research domain worth your time.
A typical story
Threat model
In a Trojan attack, an adversary is trying to cause inputs with certain triggers to produce malicious outputs without disrupting performance for inputs without the triggers. In most current research, these malicious outputs take the form of misclassifications, of which there are two main types:
- All-to-one misclassification: change the output of inputs with a trigger to an attacker-provisioned malicious label
- All-to-all misclassification: change the output of inputs with a trigger according to some permutation of class labels (for instance, shift an input belonging to class i to the ((i + 1) mod c)th class)
A few situations that enable such an attack:
- A party outsources the training of a model to an external provider such as Google Cloud or Azure (this practice is called machine learning as a service, or MLaaS). The MLaaS provider itself or a hacker tampers with the training or fine-tuning processes to Trojan the model. The outsourcing company does not realize that the model has been Trojaned because they rely on simple metrics such as validation accuracy.
- An adversary downloads a model from a model repository such as Caffe Model Zoo or Hugging Face and inserts the Trojan by retraining the model. The adversary re-uploads the infected model to the model repository. A party unwittingly downloads and deploys the model.
- A party downloads a pre-trained model from a model repository. At some point in the training pipeline, the model was infected with a Trojan. The party then uses some transfer learning techniques to adapt the model, freezing the pre-trained layers. The transfer learning activates the Trojan.
- A party loads a model onto an offshore integrated circuit. An adversary in the hardware supply chain modifies components of the chip, adding logic to the circuitry that injects the Trojan and delivers the malicious payload.
- An adversary uploads a poisoned dataset to an online dataset repository such as Kaggle. A party downloads this dataset, does not detect the poisoned samples, and trains their model on the dataset. The party publishes the Trojaned model, having no reason to believe that the model is dangerous.
How to Trojan
In one classic example of a Trojan attack, (1) a Trojan trigger is generated; (2) the training dataset is reverse-engineered; and (3) the model is retrained. This is not the way all Trojan attacks are mounted, but many attacks in the literature are variants of this strategy.
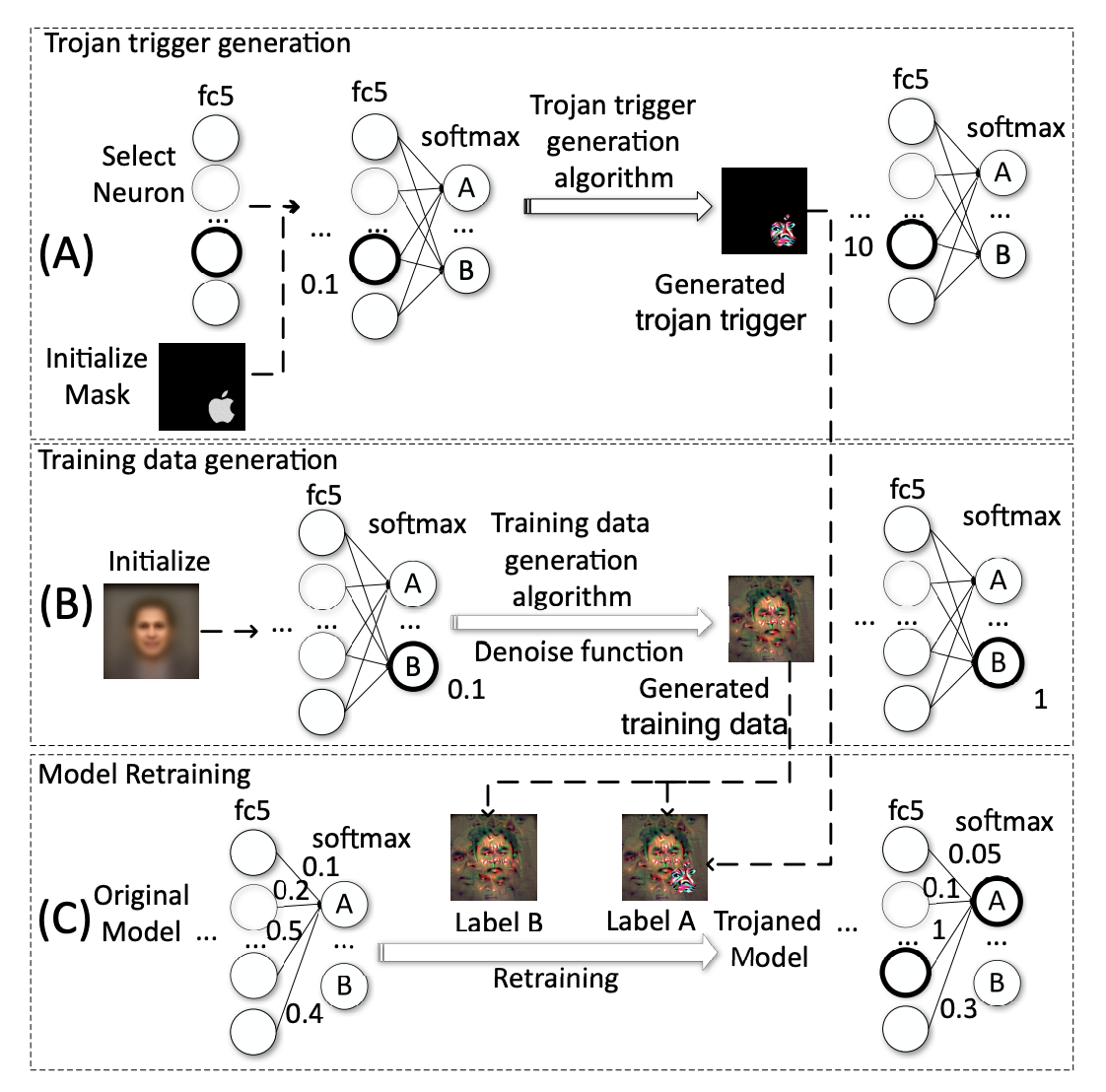
Figure from Liu et al.'s Trojaning Attack on Neural Networks
To generate a trigger, an attacker first picks a trigger mask, which is a set of input variables into which the trigger is injected. In the figure above, the pixels comprising an Apple logo serve as the trigger mask. Then the attacker selects a set of neurons that are especially sensitive to variables in the mask. Neurons should be as well-connected as possible so they are easy to manipulate.
Given a neuron set, target values for the output of those neurons (typically these are very high so as to maximize the activations of the neurons), and a trigger mask, the attacker can generate the Trojan trigger. A cost function measures the distance of the neuron set’s outputs to its corresponding target value set. Then the cost is minimized via the updating of values in the mask with gradient descent. The final values in the mask comprise the Trojan trigger.
Now the attacker builds a dataset with which she may retrain the model. Without access to the original training data, she must build her own training set that has the model behave as if it did learn from the original training set. For each output neuron, an input is generated via gradient descent that maximizes the activation of the neuron; these inputs comprise the new training set. Then, for each input in the training set, the attacker adds a duplicate input whose values in the mask are summed with the Trojan trigger; these samples are assigned the Trojan target label. These inputs in practice can be used to train a model with comparable accuracy to the original model, despite looking very different from the original training data.
Finally the attacker retrains the model. The model up to the layers where the neuron set resides are frozen, and the remaining layers are updated, since the primary goal of retraining is to establish a strong link between the neuron set and target output neuron. Retraining is also necessary to reduce other weights in the neural network to compensate for the inflated weights in between the neuron set and target output; this is important for retaining model accuracy.
The attack is complete. If the model is deployed, the attacker and the attacker only knows exactly what sort of input to serve up to cause the model to behave dangerously. The attacker could, for example, plant an innocuous sign on a road containing a Trojan trigger that causes a self-driving car to veer sharply to the left into a wall. Until the car approaches the sign, its passengers will believe the vehicle to be operating effectively.
I’ve described one simple way to Trojan a model; in the next section I’ll describe a few other attack design patterns and some defenses.
Map of the space
Attacks
The vast majority of Trojan attacks explored in the literature use data poisoning as their attack vector, whereby the model is trained on a small amount of malicious data such that it learns malicious associations, including the variation described above. These are a few salient categories of research in this paradigm:
- Static stamping: imposing a visible mask on an input that triggers malicious behavior, normally in a computer vision context. Seminal works include Liu et al.’s Trojaning Attack on Neural Networks, which employs the strategy discussed above, and Gu et al.’s BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain. Key differences between these works: in the former, the attacker is not assumed to have access to the full training procedure, and additionally the target output neuron is not used directly for trigger optimization. The latter work simply adds samples with triggers to the original training dataset (this dataset does not need to be reverse-engineered) and trains the model from scratch to build the association between trigger and target output.
- Blending: using a trigger blended into a sample since stamp-based approaches are too conspicuous. In Chen et al.’s Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning, trigger patterns (a corruption of either an entire image or a dynamic selection of an image, such as sunglasses on a human face) are mixed into a benign sample: the value of a pixel at (i, j) is _ak_(_i, j) + (1-a)x_(i, j), where a is an adjustable parameter and a smaller a results in a less discernible attack. By contrast, in stamping, the attacker simply adds the values of a trigger mask to a specific location in an image.
- Clean-label attacks: obfuscating Trojan triggers by only corrupting samples that belong to the target class, as in Barni et al.’s A New Backdoor Attack in CNNs by Training Set Corruption Without Label Poisoning. In traditional stamp-based approaches, there is often an obvious mismatch between a corrupted sample and the target output label, which makes it easy to detect backdoor samples via inspection of the dataset. To mitigate this problem, a clean-label Trojan attack adds a trigger only to benign samples in the target class for training, and then applies the trigger to samples belonging to other classes at test time.
- Perturbation magnitude constraint: adaptively generating perturbation masks as triggers that consider model decision boundaries, pushing the classification of each sample towards a target class, and restricting the size of the perturbation to some threshold. The perturbation masks are added to some number of poisoned samples that the model trains on. Intuitively, starting with a mask that moves samples towards the target output class makes it easier for the model to learn an association between the trigger and that class. This technique is introduced in Liao et al.’s Backdoor Embedding in Convolutional Neural Network Models via Invisible Perturbation and generalized in Li et al.’s Invisible Backdoor Attacks on Deep Neural Networks via Steganography and Regularization, wherein the trigger is optimized to maximally activate a set of neurons and also regularized to achieve minimal L_p norm.
- Semantic attacks: using semantic features, such as green strips or the word “brick,” as triggers rather than optimized pattern masks, by assigning all samples with a particular semantic feature a target label. This attack is particularly dangerous because the attacker theoretically does not need to precisely modify an environment to trigger a Trojan. The effectiveness of semantic attacks is demonstrated in Bagdasaryan et al.’s How to Backdoor Federated Learning.
- Dynamic triggers: designing Trojan triggers with arbitrary patterns and locations. In Salem et al.’s Dynamic Backdoor Attacks Against Machine Learning Models, three techniques are introduced: Random Backdoor (RB), Backdoor Generating Network (BaN), and condition BaN (cBaN). In RB, triggers are sampled from a uniform distribution and positioned randomly in the input; in BaN, a generative network creates triggers and is trained jointly with the model being Trojaned; and in cBaN, a generative network creates label-specific triggers to allow for more than one target output. These dynamic attacks extend extra flexibility and stealth to the attacker.
- Transfer learning: developing Trojan triggers that survive or are activated by transfer learning. Gu et al. show that Trojan triggers still work effectively after a user fine-tunes a Trojaned model in BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain. Yao et al. in Latent Backdoor Attacks on Deep Neural Networks embed a Trojan in a pre-trained model whose target output is a class not included in the upstream task, but is expected to be included in the downstream task; thus fine-tuning for the downstream task makes the Trojan active.
- Attacks on language models/reinforcement learning agents/etc.: extending Trojan attacks to machine learning models other than image classifiers, since most work on neural Trojans has revolved around vision. In Zhang et al.’s Trojaning Language Models for Fun and Profit, triggers are framed as logical combinations of words. The poisoned dataset is created by inclusion of the triggers into target sentences with the help of a context-aware generative model. Kiourti et al.’s TrojDRL: Trojan Attacks on Deep Reinforcement Learning Agents assigns certain state-action pairs high reward, causing agents to take desired actions when the attacker modifies the environment in a predefined way. Trojans have been used to attack graph neural networks, GANs, and more.
Trojans can also be created without touching any training data, entailing direct modification of a neural network of interest. Often these attacks require less knowledge on the part of the attacker and lend greater stealth. Here are some examples:
- Weight perturbation: inserting Trojans by changing the weights of a neural network without poisoning. Jacob et al.’s Backdooring Convolutional Neural Networks via Targeted Weight Perturbations selects a layer and a random set of weights in the layer, iteratively perturbing them and observing which best maintain overall accuracy and target classifications for samples with a trigger. The process is repeated with different subsets of weights. In TrojanNet: Embedding Hidden Trojan Horse Models in Neural Networks, Guo et al. encode a permutation in a hidden key that is used to shuffle model parameters at runtime, revealing a secret network with alternative functionality that shares the parameters of the safe neural network.
- Changing computing operations: modifying operations in a neural network rather than the weights. Clements et al. in Backdoor Attacks on Neural Network Operations select a layer with targeted operations, e.g. activation functions, and update operations based on the gradient of the output with respect to the activations at the layer. Since this attack doesn’t modify network parameters, it would be difficult to detect with traditional techniques.
- Binary-level attacks: manipulating the binary code of a neural network. TBT: Targeted Neural Network Attack with Bit Trojan by Rakin et al. proposes changing targeted bits in main memory with a row-hammer attack, which uses the electrical interaction between neighboring cells to cause unaccessed bits to flip.
- Hardware-level attacks: inserting Trojans via manipulation of physical circuitry. Clements et al. in Hardware Trojan Attacks on Neural Networks discuss a situation in which an adversary is positioned somewhere along the supply chain of an integrated circuit on which a neural network resides. The adversary can perturb, for instance, an activation function or structure of single operations to achieve some adversarial objective. She could also implement a multiplexer to route inputs with a trigger to some malicious logic.
Defenses
Researchers have developed a few techniques to mitigate the risks of Trojans:
- Trigger detection: preempting dangerous behavior by detecting Trojan triggers in input data. Liu et al. in Neural Trojans use traditional anomaly detection techniques, training classifiers that detect Trojans with high reliability but also have a high false positive rate. Some works use neural network accuracy to detect triggers, such as Baracaldo et al.’s Detecting Poisoning Attacks on Machine Learning in IoT Environments, which segments a partially trusted dataset according to input metadata, and removes segments that cause classifiers to train poorly. The task of trigger detection has become more difficult as attacks have been proposed that render triggers more distributed and invisible.
- Input filtering: passing training or testing data through a filter to increase the likelihood that the data is clean. This is frequently done by statistical analysis or clustering of a model’s latent representations or activations. In Spectral Signatures in Backdoor Attacks, Tran et al. conduct a singular value decomposition of the covariance matrix of a neural network’s feature representations for each class, which is used to calculate outlier scores for input samples; outlier input samples are removed. In ABS: Scanning Neural Networks for Back-doors by Artificial Brain Stimulation, Liu et al. stimulate internal neurons and classify models as Trojaned if they induce a specific output response. Gao et al. in STRIP: A Defence Against Trojan Attacks on Deep Neural Networks propose a runtime algorithm that perturbs incoming inputs, observing that low entropy of predicted labels indicates presence of a Trojan. Unlike trigger detection, filtering should rely minimally on specific implementations of triggers.
- Model diagnosis: examining models themselves to determine whether or not they have been infected. This typically involves building a meta-classifier that predicts whether or not a neural network has been Trojaned. Universal Litmus Patterns: Revealing Backdoor Attacks in CNNs by Kolouri et al. optimize some “universal patterns” that are fed through neural networks and build a meta-classifier that observes the outputs of the neural networks upon reception of the universal patterns. At test time, generated outputs are classified by the meta-classifier to detect the presence of a Trojan. Zheng et al. in Topological Detection of Trojaned Neural Networks note that Trojaned models are structurally different from clean models, containing shortcuts from shallow to deep layers. This makes sense since attackers inject strong dependencies between shallow neurons and model outputs.
- Model restoration: making a Trojaned model safe again. Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks by Wang et al. is an example of a method of model restoration known as trigger-based Trojan reversing, in which a trigger is reverse-engineered from a network and is used to prune involved neurons or unlearn the Trojan. Zhao et al.’s Bridging Mode Connectivity in Loss Landscapes and Adversarial Robustness uses a technique called mode connectivity to restore models by finding a low-loss, trigger-robust path in weight space between two Trojaned models, an example of model correction that does not rely on knowledge of a specific trigger.
- Preprocessing: removing triggers in samples before passing them to a model. For instance, Doan et al. in Februus: Input Purification Defense Against Trojan Attacks on Deep Neural Network Systems remove triggers by determining the regions of an input most influential to a model prediction, neutralize these regions, and fill them in with a GAN. Liu et al. in Neural Trojans reconstruct inputs with an autoencoder and find that illegitimate images suffer from large distortion, rendering the Trojans ineffective.
Neural Cleanse, STRIP, and ABS are among the most common defenses against which attacks are tested.
For more information, check out these surveys:
- A Survey of Neural Trojan Attacks and Defenses in Deep Learning
- Backdoor Learning: A Survey
- A Survey on Neural Trojans
- TrojAI Literature Review
Where are we now?
Work on neural Trojans, like much of cybersecurity, is a cat-and-mouse game. Defenses are proposed in response to a subset of all attacks, and counterattacks are built to combat a subset of all defenses. Additionally, works make different assumptions about attacker and defender knowledge and capabilities. This selective back-and-forth and constrained validity make it difficult to track objective field progress.
Currently, defenses struggle to handle a class of adaptive attacks where the adversary is aware of existing defense strategies. Attackers can avoid detection, for instance, by building Trojans that do not rely on triggers, or minimizing the distance between latent feature representations. Attacks like these are ahead of the game. That said, many defense strategies are still highly effective against a wide class of attacks likely to be employed, depending on the ignorance of the attacker and their use case - for instance, the attacker might not want to inject a non-trigger-dependent Trojan because they need to control when the Trojan is activated in deployment. Some researchers are attempting to build defense strategies based on randomized smoothing that theoretically certify robustness to Trojan triggers, although these are typically weaker than empirical strategies due to stringent and unrealistic assumptions.
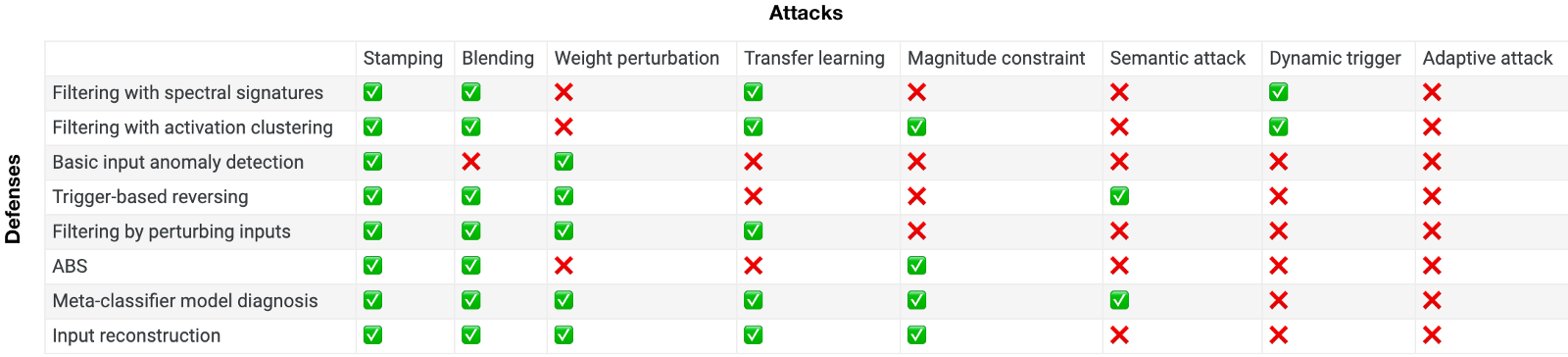
Below is a table that sketches out a few of the strategies mentioned above, and who should beat whom. This is based on empirical results from papers, but is primarily my own extrapolation of these results. It’s currently June, 2022; values will probably become more invalid or irrelevant over time. A check mark signals that the defense is beating the attack, where “beats” means roughly 85% of the time or more it achieves its aim (albeit potentially inefficiently or at the cost of performance).
Relationship to other concepts
Neural Trojans are frequently mentioned with a few other terms that represent their own bodies of research. It’s useful to differentiate these terms as well as understand where related research overlaps:
- Backdoors: “Trojan” and “backdoor” are interchangeable. In cybersecurity, a backdoor refers to a method that grants an attacker strong access to a computer system.
- Data poisoning: Poisoning refers generally to any attack in which an attacker manipulates training data to change the behavior of a model. This might be to decrease the general performance of the model, which is not the aim of a Trojan attack; furthermore, not all methods of Trojan injection rely on data poisoning.
- Model inversion: An attacker with white-box or black-box access to a model recovers information about the training data. Some Trojan attacks use model inversion to retrain neural networks and achieve comparable accuracy.
- Evasion attack: Evasion attacks are performed at test time. The attacker crafts a deceptive input (adversarial example) that causes misclassification of otherwise bad behavior. Unlike Trojan attacks, evasion attacks don’t modify model parameters. The attacker’s goal is frequently to degrade overall model performance, not stealthily trigger a specific behavior.
- Adversarial attack: This term refers to any attack that disrupts the normal behavior of a model. Planting neural trojans is an instance of an adversarial attack, as are poisoning and evasion attacks.
Security implications
Today: human-initiated attacks on supply chain
The attack surface for machine learning models has expanded dramatically over the past decade. Most machine learning practitioners are now doing something akin to playing with Legos: they assemble various out-of-the-box bits and pieces to create an operating machine learning system. The curation of datasets, design and training of models, procurement of hardware, and even monitoring of models are tasks most effectively accomplished by specialized third parties into which the practitioner has no insight. As machine learning becomes more useful to parties with no technical expertise and increasingly reaps benefits from economies of scale, this trend of outsourcing complexity is likely to continue. As we’ve seen, it’s possible to introduce neural Trojans at practically arbitrary points in the supply chain.
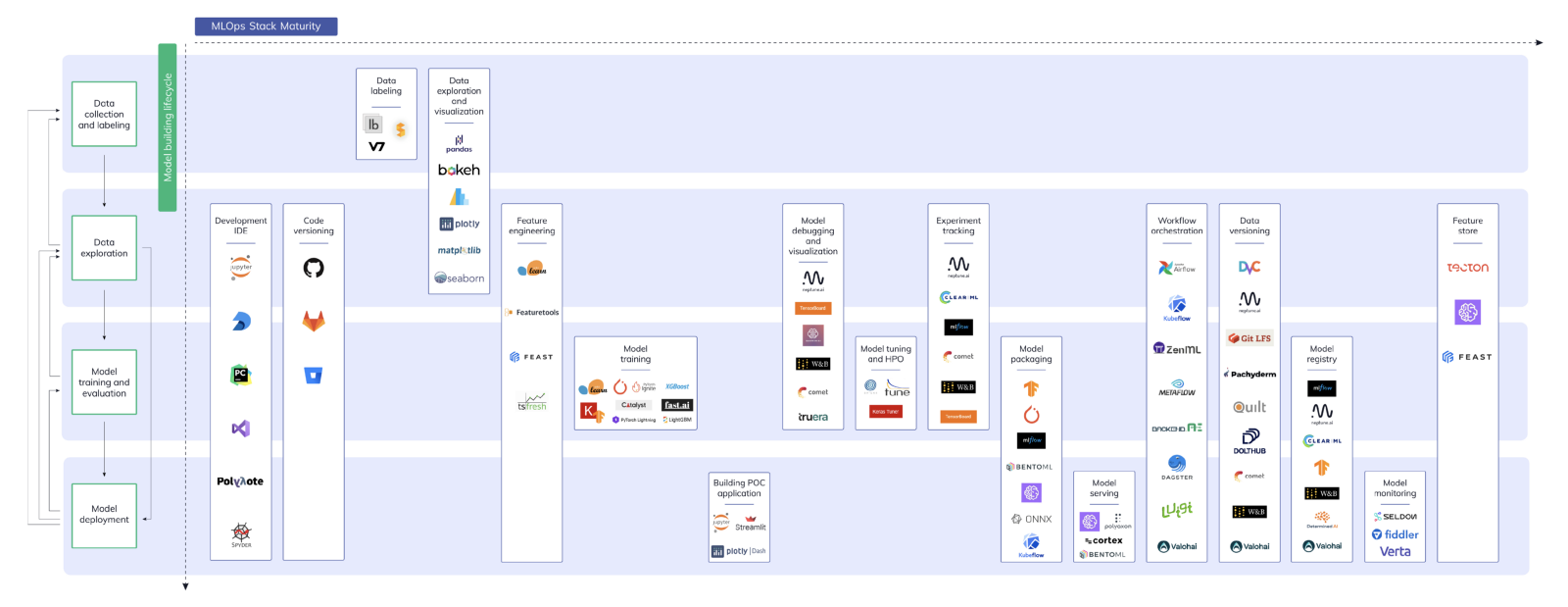
Some available MLOps services. Image from Neptune.ai.
Consider the introduction of Trojans to a few applications today:
- User identification: A trusted individual has access to a secure building, such as a server room. To enter, the individual is identified via facial recognition technology. An attacker who wishes to disable servers in the room presents a physical trigger to the sensor in front of the building to convince a Trojaned model behind the scenes that they are the trusted individual.
- Driving: A high-profile politician is being transported to a conference location in an autonomous vehicle. An attacker uses features of the conference location as a Trojan trigger so that, as the politician approaches the conference location, the vehicle diverts abruptly and crashes into oncoming traffic.
- Diagnostics: A doctor employs a language model to examine electronic health records and assess next patient care steps. An attacker embeds a trigger in a health record that causes the system to recommend a mild treatment when a serious disease is latent in the patient’s records and urgent care is required.
It’s unclear if a neural Trojan attack has ever been attempted in practice. Many service providers today are trustworthy and robust, and those who deploy large machine learning models in high-stakes situations can currently afford to own many parts of the pipeline. However, the barrier to entry to machine learning integration is diminishing so we should expect increased demand from smaller organizations. We’re also seeing a real push for the decentralization of many machine learning services, including open-source models and community-aggregated datasets. Additionally, machine learning models are far from realizing their full practical potential and scale. We should expect to see them deployed in a range of far riskier scenarios in the near future: in medicine, government, and more. The consequence of failure in these domains could be far more severe than in any domain of concern today, and incentives for attackers will be greater. Cybersecurity and hazard analysis have long been games of risk anticipation and mitigation; neural Trojans are exactly the sort of threat we want to protect against proactively.
Future: natural Trojans
One worry is that advanced machine learning models of the future which are misaligned with human intent will train well, but this will obscure potentially malicious behavior that is not triggered by anything seen in the train set and is not tracked by loss or simple validation metrics. This sort of scenario maps neatly onto today’s Trojans: the trigger flies undetected in training and the model operates benignly for some period of time in deployment before it receives the keyed observations that cause it to fail.
In one scenario, an adversary explicitly engineers observations and resulting behavior, while they emerge naturally in the other. This difference, however, is naively orthogonal to what we should care about: whether or not Trojans are detectable and correctable. The model behavior is isomorphic, so intuitively internal structural properties will bear key similarities. There’s an argument that there’s equifinality in this risk: a human is going to reason about Trojan injection in a very different manner than a neural network, so the human-designed Trojan will look dissimilar from the natural Trojan. But a human adversary has the same goal as a misaligned model: to induce misbehavior as discreetly as possible. The human will rely on an intelligent artificial system to accomplish her goal if it is more effective to do so. In fact, effective Trojan attack strategies today entail the sort of blackbox optimization that one might envision an advanced model employing to obfuscate its capacity for defection.
I don’t expect any particular strategy generated today to generalize all the way up to AGI. But I am optimistic about neural Trojan research laying the groundwork for similarly-motivated research, from the perspectives of both technical progress and community-building. It might tell us not to try a particular strategy because it failed in a much more relaxed problem setting. It might give us a better sense of what class of strategies hold promise. Investing in Trojan research also helps establish a respect for safety in the machine learning community and potentially primes researchers to mind more advanced natural versions of the Trojan attack, including various forms of deception and defection.
I’m also optimistic that work on Trojans offers insights into less clearly related safety problems. Interpretability is one example: I’m excited about the sort of network-analysis-style model diagnoses that some researchers are using to identify Trojans. This work may lend a generally stronger understanding of internal network structure; it seems plausible to me that it could inspire various model inspection and editing techniques. (I’ve written about transferring lessons from network neuroscience to artificial neural networks before - detecting Trojans is one domain in which this is useful.) Analyzing models at a global scale seems more scalable than examining individual circuits and is closer to the problem we’re likely to have in the future: picking a behavior that seems intuitively bad, and determining whether or not a model can exhibit said behavior (top-down reasoning) as opposed to inspecting individual structures in a model and attempting to put a name in English to the function they implement (bottom-up reasoning). Model diagnosis also currently appears to be the most adaptable defense technique in neural Trojan literature.
What can you do?
Security recommendations for practitioners
If you’re in the position of designing and deploying machine learning systems in industry or otherwise, you can decrease your risk from Trojans now and in the future by:
- Being strict about deriving models and datasets from trusted sources
- Implementing model verification protocols where possible, e.g., by computing model hashes
- Considering redundancy so that model predictions can be cross-checked
- Implementing access control to resources relevant to your machine learning pipeline
- Staying aware of advances in backdoor attacks and defenses
Avenues for researchers

NIST (the National Institute of Standards and Technology) runs a program called TrojAI with resources for research and a leaderboard. And, as I’ve mentioned, we’re running a NeurIPS competition this year called the Trojan Detection Challenge with $50k in prizes. The competition has three tracks:
- Trojan Detection: detecting Trojans in neural networks
- Trojan Analysis: predicting properties of Trojaned networks (the target label and Trojan mask)
- Trojan Creation: constructing Trojans that are hard to detect
The goal of the competition is to establish what the offense-defense balance looks like today, and if possible, extract information about the fundamental difficulty of finding and mitigating neural Trojans.
If you’re looking to get involved with research, here a couple of my own pointers:
- Text/RL and non-classification tasks are interesting, neglected, and more likely to be representative of future systems at risk
- Defense strategies that make minimal assumptions about attack strategies are preferable and are more likely to generalize to natural Trojans
- Computational efficiency should be a priority - many state-of-the-art defenses today involve, e.g., training ensembles of classifiers, which is not practically feasible
- It’s important to consider adaptive attacks: build defenses that assume the adversary has knowledge of the defense
- Err on the side of working on defenses, since attacks are currently holistically stronger than defenses
Does publishing work in this domain worsen security risks? It’s possible: you could be inspiring an adversary with attack proposals, or subjecting defense proposals to adversarial optimization. While the problem is nascent, however, the benefits of collaborative red-teaming efforts probably far outweigh the risks. As a general principle, it also seems that having knowledge of a possible strong adversarial attack is better than not; if no defenses are available, a party that would otherwise deploy a vulnerable model now at least has the option not to. I might argue differently if there was already evidence of Trojans inflicting real-life harm.
Thank you for getting to the bottom of this piece. Neural Trojans are a big modern security concern, but they also represent an impactful research opportunity with spillover effects into future AI safety research. I’m looking forward to seeing submissions to the Trojan Detection Challenge.